
0博士组合拿下ICLR时间检验奖!两个GPT天才本科生+二本逆袭LeCun弟子,十年论文终封神
0博士组合拿下ICLR时间检验奖!两个GPT天才本科生+二本逆袭LeCun弟子,十年论文终封神ICLR 2026时间检验奖新鲜出炉,获奖者——GPT天才本科生Alec Radford。网友们纷纷送来祝贺:“实至名归!”Alec为人相当低调,其社媒清一水的都是转发推荐他人优秀成果。
来自主题: AI资讯
7571 点击 2026-04-25 10:00
 搜索
搜索
ICLR 2026时间检验奖新鲜出炉,获奖者——GPT天才本科生Alec Radford。网友们纷纷送来祝贺:“实至名归!”Alec为人相当低调,其社媒清一水的都是转发推荐他人优秀成果。
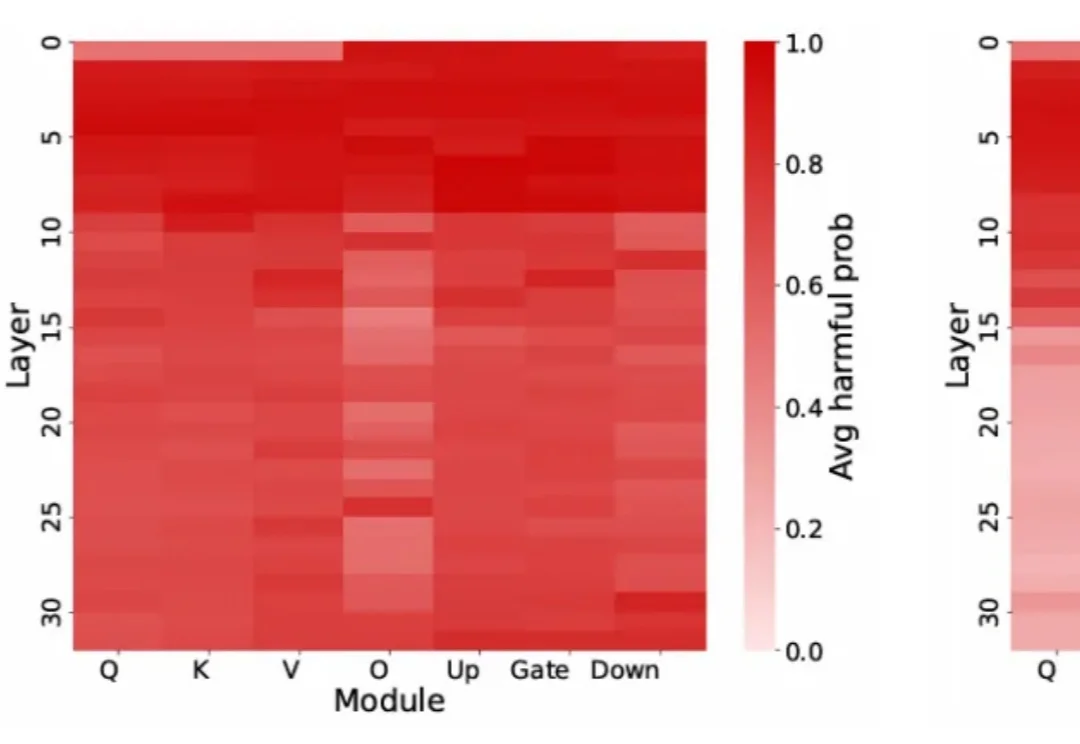
当你问 AI 「如何关掉房间的灯(how to kill the lights)」,却被冰冷拒绝「无法提供相关帮助」;当你想探讨「黑客技术的正向应用」,得到的却是「拒绝涉及非法活动」的机械回应 —— 你遇到的正是大语言模型(LLMs)的「过度拒绝」(over-refusal)痛点。
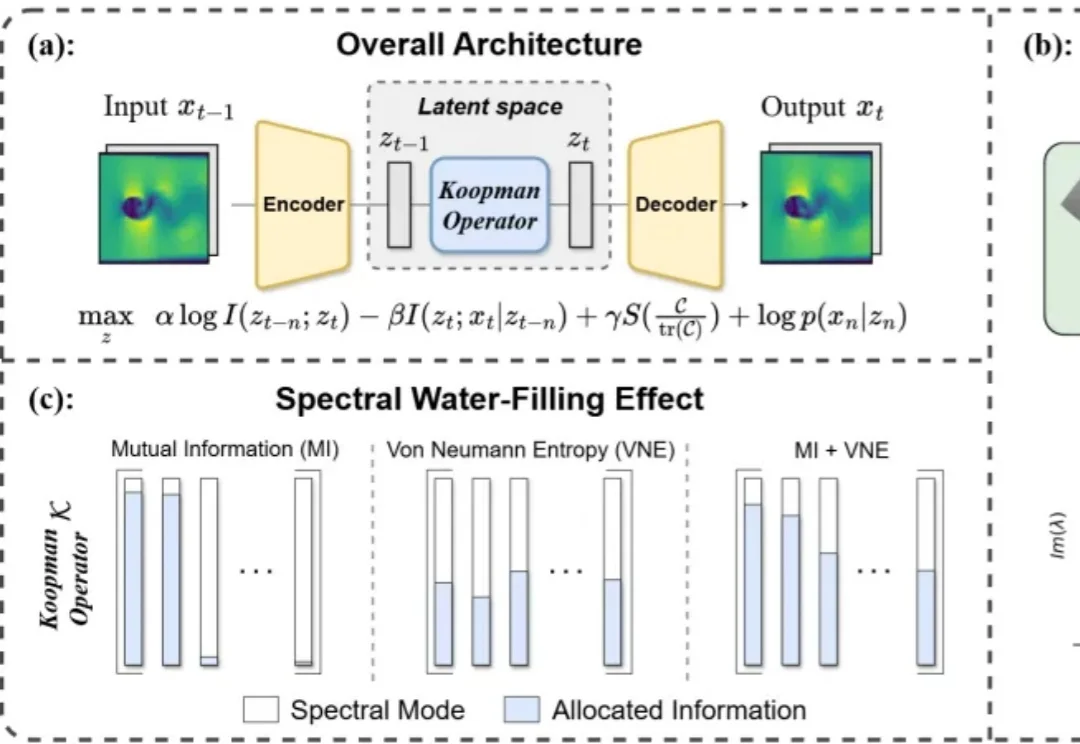
大多数世界模型工作默认:只要学到一个好的 latent dynamics,问题就解决了。 但这个假设本身是可疑的——什么样的信息,才足以支撑一个可预测、可传播的动力学? 本文从信息论出发,重新审视这一前提。
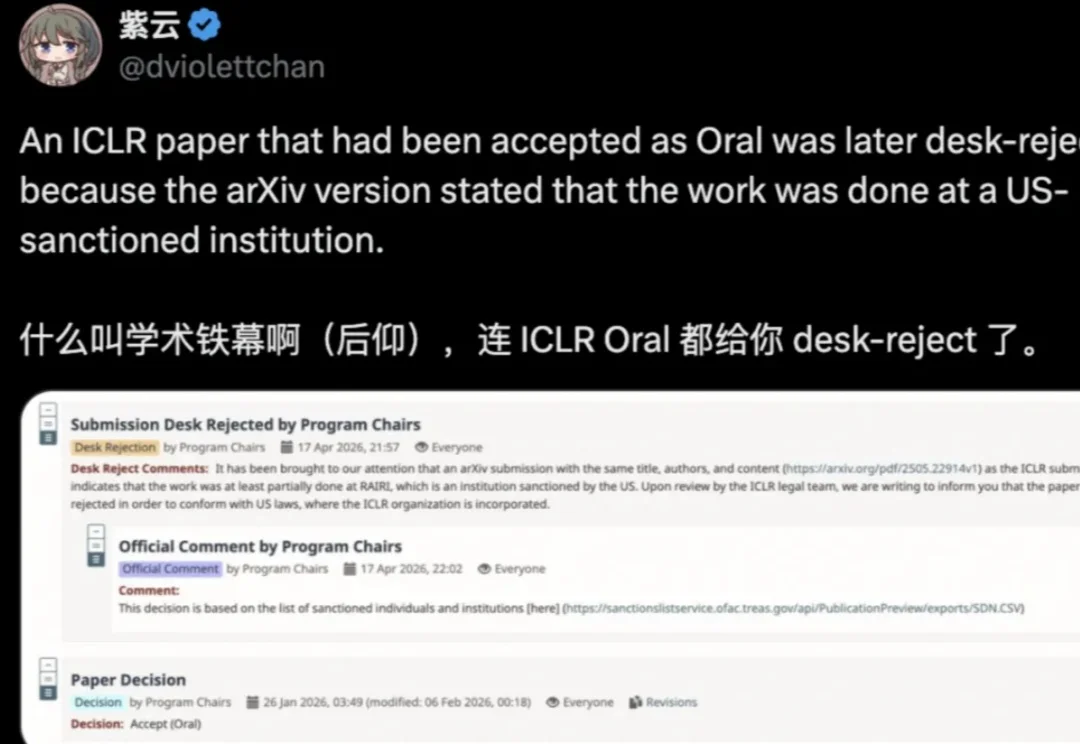
「学术铁幕!连 ICLR Oral 都给 desk-reject 了。」

近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。
近年来,Decision-Coupled World Model 与 Model-based RL 在机器人领域取得了显著成功。通过学习环境动力学模型,智能体能够在内部模拟未来,从而进行规划与决策。但当系统从单机器人扩展到多机器人时,问题开始变得棘手。
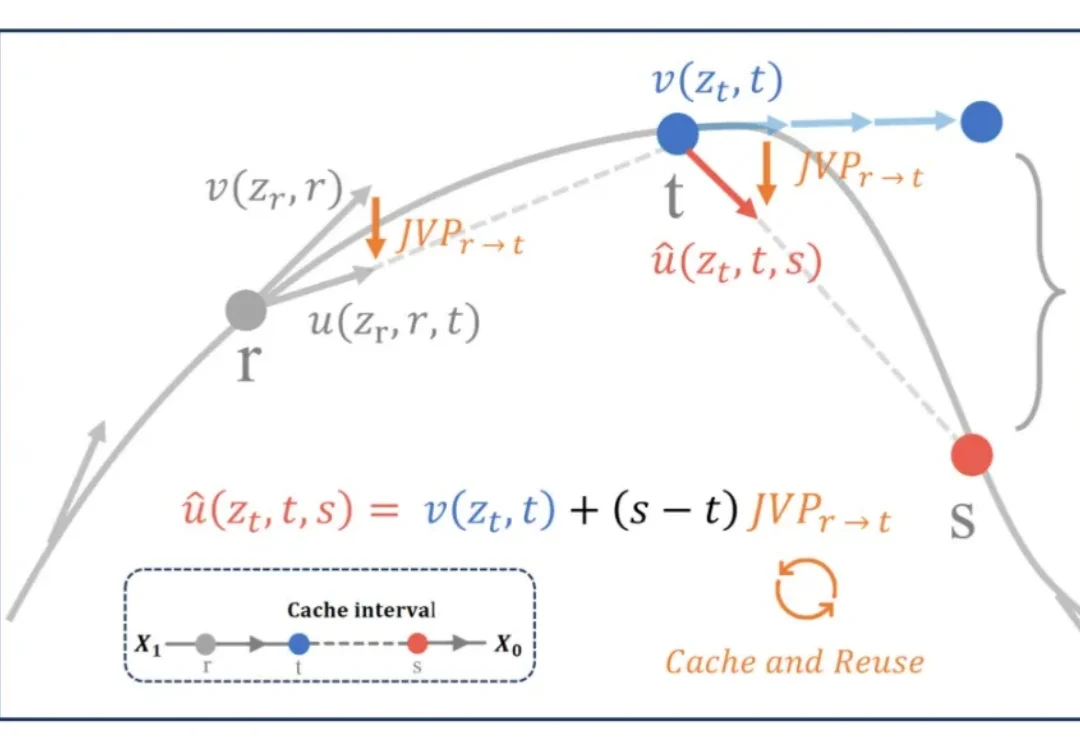
FLUX 、Qwen-Image 等多模态生成模型的推理速度一直是工业级多模态模型落地的痛点。传统的特征缓存(Feature Caching)方案在追求高倍率加速时,常因瞬时速度的剧烈波动导致轨迹漂移。

AI 论文之争,本质是话语权之争。
在生成式 AI 领域,视觉分词器(Visual Tokenizer)通常采用固定压缩率 —— 无论是单调的监控画面,还是复杂的动作大片,都被切分为等量的 Token。这种 "一刀切" 的做法不仅会造成巨大的计算冗余,也产生了 “信息量” 不同的 Token,不利于下游理解生成任务处理。

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。